Postgresql и ZFS
Почему мне нужен ZFS вместо встроенного TOAST?
Для tghub я использую довольно дешевый VPS с только 1тб хранилища. Поэтому мне нужно сжимать мои данные. Несмотря на то, что в Postgresql есть функция TOAST (Техника хранения атрибутов увеличенного размера), она мне не подходит. По умолчанию, TOAST срабатывает для текстовых данных размером 2 кБ. Таблица сообщений моего проекта tghub имеет почти 3 миллиарда строк и продолжает расти, но они обычно маленькие, поэтому TOAST не сработает для меня. Я решил попробовать хранить данные сообщений в отдельном пространстве таблиц и переместить их на файловую систему ZFS.
Общая схема
Текущая производительность
Мне удалось достичь хорошего баланса между дисками.
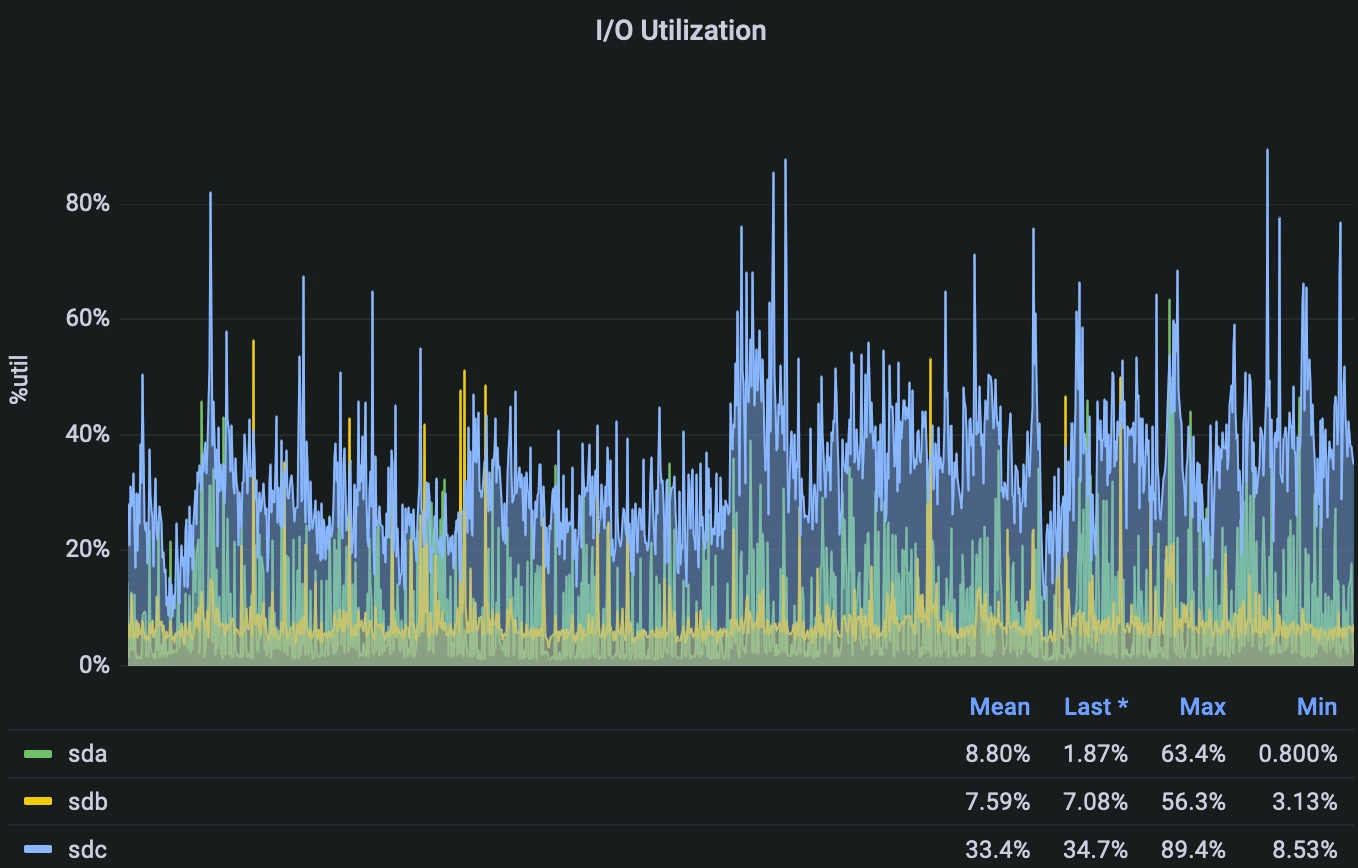
- sda -- Default Tablespace
- sdb -- ZFS Tablespace
- sdc -- Index Tablespace
Во время нормальной рабочей нагрузки диск с индексами самый загруженный, что ожидаемо. На диске размещены 2 индекса, которые изменяются случайными вставками (~800 строк в секунду). Лучше не перегружать диск с основным пространством таблиц, так как там хранятся индексы для поиска. Когда много пользователей решат что-то искать одновременно, этот диск должен иметь запас мощности.
Настройка Postgresql и ZFS
Я сделал некоторую дополнительную настройку для zfs и postgresql:
- Отключил TOAST, чтобы не сжимать данные дважды:
ALTER TABLE channel_message
ALTER COLUMN text SET STORAGE EXTERNAL;- Следовать рекомендациям zfs для баз данных и установить размер сектора в 32К. По умолчанию размер составляет 128К. Это слишком много и вызывает нежелательные чтения. Мы можем даже установить размер сектора в 8К, но это уменьшает коэффициент сжатия. Поэтому важно найти баланс между скоростью чтения (меньший сектор) и коэффициентом сжатия (больший сектор)
sudo zfs set recordsize=32K datapool- Выключить обновленное время, это действительно не имеет смысла:
sudo zfs set atime=off datapool- Установить компрессию на zstd, она медленнее, чем lz4, но имеет лучший коэффициент сжатия (может быть x2 для текстовых данных):
sudo zfs set atime=off datapoolНа данный момент моя таблица channel_message с почти 3 миллиардами строк занимает 1061Гб несжатых данных против 291Гб сжатых на диске ZFS. Это более чем 3x коэффициент!